
Hive文件存储格式及优缺点
textfile
默认的文件格式,行存储。建表时不指定存储格式即为textfile,导入数据时把数据文件拷贝至hdfs不进行处理。
优点:最简单的数据格式,便于和其他工具(pig, grep, sed, awk)共享数据、便于查看和编辑;加载较快。
缺点:耗费存储空间,I/O性能较低;Hive不进行数据切分合并,不能进行并行操作,查询效率低。
适用于小型查询,查看具体数据内容的测试操作。
sequencefile
行存储,含有键值对的二进制文件。
优点:可压缩、可分割,优化磁盘利用率和I/O;可并行操作数据,查询效率高。
缺点:存储空间消耗最大;对于Hadoop生态系统之外的工具不适用,需要通过text文件转化加载。
rcfile
行列式存储。先将数据按行分块,同一个record在一个块上,避免读一条记录需要读多个block;然后块数据列式存储。
优点:可压缩,高效的列存取;查询效率较高。
缺点:加载时性能消耗较大,需要通过text文件转化加载;读取全量数据性能低。
orcfile
![]()
优化后的rcfile,行列式存储。优缺点与rcfile类似,查询效率最高。适用于Hive中大型的存储、查询。
parquet
![]()
列式存储,以二进制方式存储。
优点:可压缩,高效的列存取;优化I/O。
缺点:不支持upadate操作(数据写入后不可更改),不支持ACID。
Hive压缩算法对比
Hive压缩算法包含6种,其中包含default、gzip、bzip2、lzo、lz4、snappy等压缩格式,具体采用压缩算法及比对详细如下:
检查Hadoop本地库支持压缩格式
检查命令:hadoop checknative
hadoop checknative 命令检查本地库是否支持压缩,若不支持,需要进行源码编译将native library编译进Hadoop。
native library checking:
hadoop: true /opt/cloudera/parcels/cdh-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
zstd: true /opt/cloudera/parcels/cdh-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop/lib/native/libzstd.so.1
snappy: true /opt/cloudera/parcels/cdh-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop/lib/native/libsnappy.so.1
lz4: true revision:10301
bzip2: true /lib64/libbz2.so.1
openssl: true /lib64/libcrypto.so
isa-l: true /opt/cloudera/parcels/cdh-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop/lib/native/libisal.so.2
Hive压缩算法设置
default压缩格式
![]()
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.defaultcodec;
gzip压缩格式
![]()
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.gzipcodec;
bzip2压缩格式
![]()
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.bzip2codec;
lzo压缩格式
![]()
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=com.hadoop.compression.lzo.lzopcodec;
lz4压缩格式
![]()
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec= org.apache.hadoop.io.compress.lz4pcodec;
snappy压缩格式
![]()
set hive.exec.compress.output=true;
set mapred.compress.map.output=true;
set mapred.output.compress=true;
set mapred.output.compression=org.apache.hadoop.io.compress.snappycodec;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.snappycodec;
set io.compression.codecs=org.apache.hadoop.io.compress.snappycodec;
压缩算法测试及结果比对
测试案例
![]()
测试一个Hive在不同的压缩格式下进行对压缩比、查询效率、插入效率进行结果比对。
测试环境
![]()
大数据平台产品:CDH6.1
节点个数:2+6
内存:256G
CPU:64核
测试数据
![]()
表名称:ods.o_cor_test
源文件大小:3.8G
查询速度:19.41S
建表语句:
CREATE TABLE ODS.O_COR_TEST
( BOOK_ID STRING,
EVENT_ID STRING,
TRX_ID_IN STRING,
TRX_ID_OUT STRING,
LINE_ID STRING,
HEADER_ID STRING,
BATCH_ID STRING,
BOOK_TYPE STRING,
ASSET_TYPE STRING,
CATEGORY_ID STRING,
INTERFACE_CONTROL_ID_IN STRING,
INTERFACE_CONTROL_ID_OUT STRING,
EFFECTIVE_DATE DATE,
INEFFECTIVE_DATE DATE,
DATA_DATE DATE,
ACCOUNTING_DATE DATE,
EVENT_TYPE STRING,
ACTIVE_CODE STRING,
AMORTIZED_COST STRING,
FAIR_COST STRING,
CONTACT_IN STRING,
CONTACT_OUT STRING,
COST STRING,
INT STRING,
INT_ADJUST STRING,
EVALUATION_ADJUST STRING,
FAIR_COST_ADJUST STRING,
CV_RESERVE STRING,
RV_RESERVE STRING,
HV_RESERVE STRING,
RA_COST STRING,
LEASE_COST STRING,
LEASE_CV_RESERVE STRING,
LEASE_RV_RESERVE STRING,
LEASE_HV_RESERVE STRING,
INVESTMENT_INCOME STRING,
INVESTMENT_LOSS STRING,
FAIR_COST_GAIN_LOSS STRING,
V_LOSS STRING,
OTHER_INCOME STRING,
ORIGINAL STRING,
TRANS_INT_IN STRING,
TRANS_INT_OUT STRING,
INT_ACCRUED STRING,
EXPENSE STRING,
RECOV_ORIGINAL STRING,
RECOV_TRANS_INT_IN STRING,
RECOV_TRANS_INT_OUT STRING,
RECOV_INT_ACCRUED STRING,
RECOV_EXPENSE STRING,
LOSS_ORIGINAL STRING,
LOSS_TRANS_INT_IN STRING,
LOSS_TRANS_INT_OUT STRING,
LOSS_INT_ACCRUED STRING,
LOSS_EXPENSE STRING,
LEASE_ORIGINAL STRING,
GUARANTEE1 STRING,
GUARANTEE2 STRING,
GUARANTEE3 STRING,
BALANCE_OUT STRING,
LY_INVESTMENT_INCOME STRING,
LY_INVESTMENT_LOSS STRING,
LY_FAIR_COST_GAIN_LOSS STRING,
LY_V_LOSS STRING,
LAST_UPDATE_DATE DATE,
LAST_UPDATED_BY STRING,
CREATION_DATE DATE,
CREATED_BY STRING,
LAST_UPDATE_LOGIN STRING,
ATTRIBUTE_CATEGORY STRING,
ATTRIBUTE1 STRING,
ATTRIBUTE2 STRING,
ATTRIBUTE3 STRING,
ATTRIBUTE4 STRING,
ATTRIBUTE5 STRING,
ATTRIBUTE6 STRING,
ATTRIBUTE7 STRING,
ATTRIBUTE8 STRING,
ATTRIBUTE9 STRING,
ATTRIBUTE10 STRING,
INT_AMORTIZED STRING,
START_DATE DATE,
END_DATE DATE,
DEL_FLAG STRING
)
测试方法
本测试采用每次开启Hive压缩模式并设置Hive的压缩算法,对于Hive每种文件存储格式新建Hive表,并向不同分区插入数据,测试并记录各种压缩算法的压缩效率、查询速率、插入速度。
注:每次设置终端退出后设置无效。
查询速率测试sql语句:
select count(*) from ods.o_cor_test where etl_date=
压缩算法对比
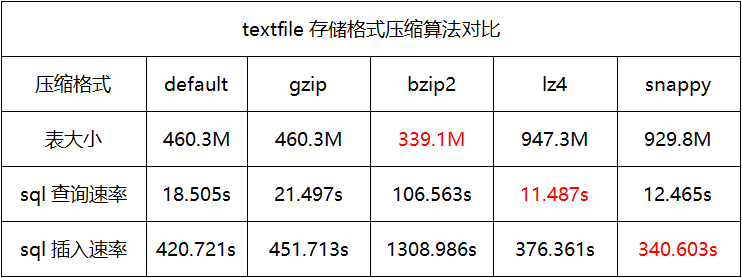
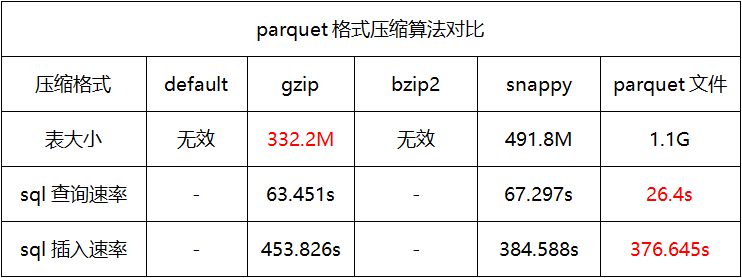

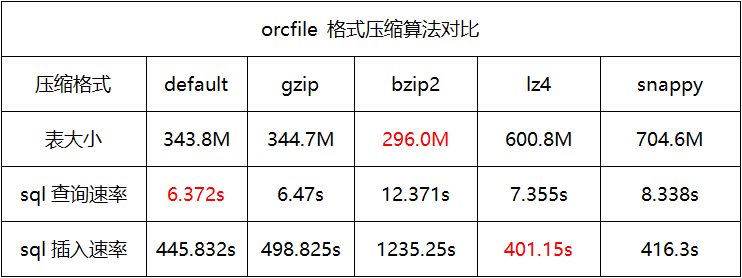
测试结果
当应用场景多为查询时,建议使用orcfile存储格式且压缩格式为default。
当应用场景多为存储时,建议使用orcfile存储格式且压缩格式为bzip2。
当应用场景多为插入时,建议使用sequencefile存储格式且压缩格式为snappy。
一般常用存储格式为orcfile且压缩格式为default。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

